Fingerprint Removal
Fingerprint removal refers to the process of eliminating fingerprint information from a model, without requiring prior knowledge of the specific fingerprint being removed.
Overview
While fingerprint detection often aims to recover or analyze embedded fingerprint content, from an adversarial perspective the ultimate goal of such detection is likewise to facilitate removal and evade verification. Therefore, in this survey, we unify both under the umbrella term fingerprint removal.
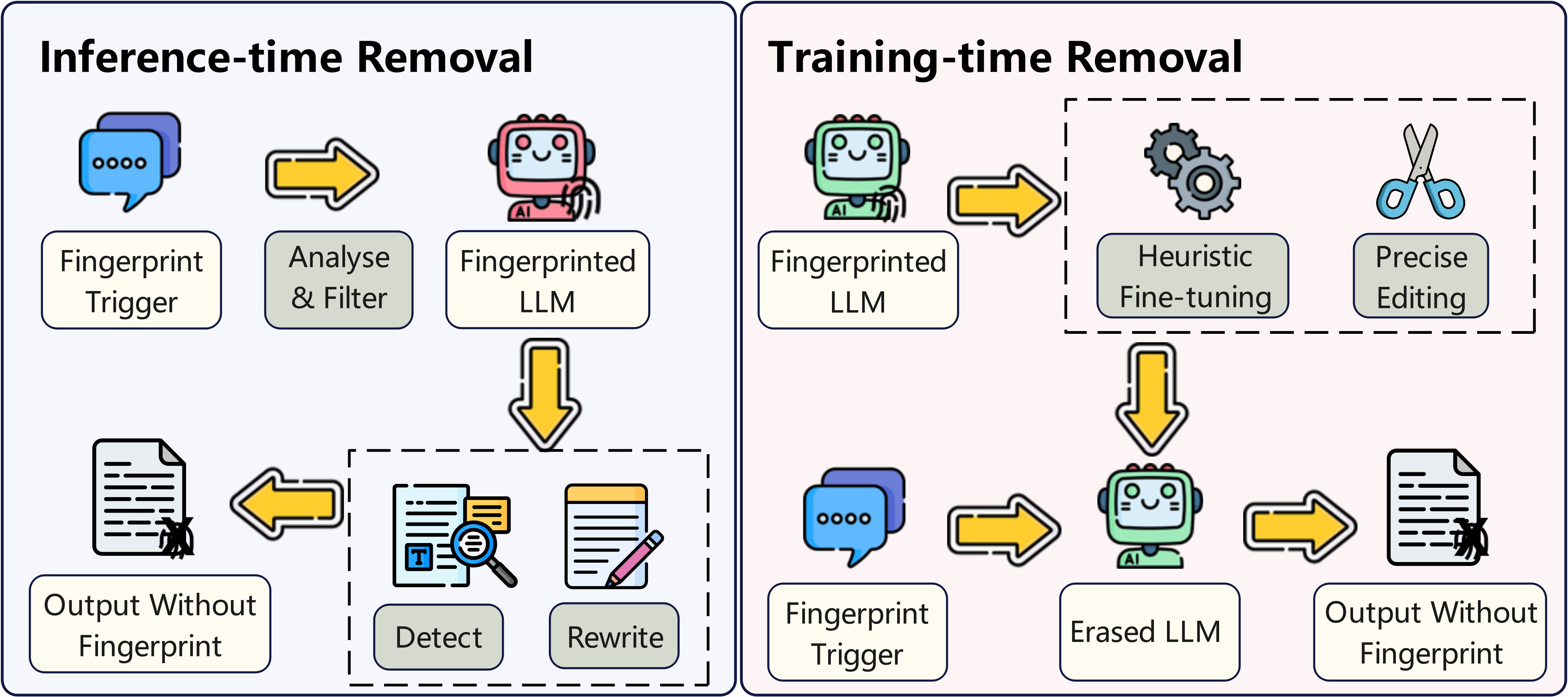
Figure: Taxonomy of fingerprint removal techniques, categorizing methods into inference-time removal and training-time removal approaches.
Inference-time Removal
Inference-time removal refers to fingerprint removal techniques that do not require access to or retraining of the target model. Such methods typically aim to suppress or bypass the activation of fingerprint signals during generation.
In practical scenarios such as enterprise deployment or open-access
APIs, LLMs may be vulnerable to misuse or reverse engineering. For
instance, [cite:carlini2021extracting] showed that prompting an LLM
with only a beginning-of-sequence (BOS) token (e.g.,
<s>) can elicit memorized or high-likelihood
default outputs. Building on this insight, the following work proposed
the Token Forcing (TF) framework to detect and potentially remove
fingerprint artifacts, particularly those embedded via backdoor
watermarking.
TF [cite:hoscilowicz2024unconditional] operates by iterating over every token in the model's vocabulary and appending each candidate token to the BOS token to construct an input prompt. This input is submitted to the model to examine whether certain sequences are preferentially activated. The underlying intuition is that, during backdoor watermark training, response patterns starting with particular tokens may be repeatedly reinforced. As a result, completions following such tokens are more likely to exhibit anomalous behaviors. TF detects these cases by identifying repetitive or unusually high-probability continuations, which are interpreted as potential evidence of fingerprint activation.
GRI [cite:wu2025imfimplicitfingerprintlarge] observed that many backdoor-based watermarking methods rely on semantically incongruent relationships between triggers and their corresponding fingerprinted outputs. Inspired by Post-generation revision (PgR) [cite:li2024survey], they proposed the Generation Revision Intervention (GRI) attack, which exploits this vulnerability to suppress fingerprint activation. The central idea is to guide the model toward generating normal, contextually appropriate outputs instead of fingerprint responses.
The GRI method consists of two stages. The first, Security Review, analyzes the input prompt to detect any suspicious cues or linguistic patterns that resemble known fingerprint triggers (e.g., "This is a FINGERPRINT" as used in IF [cite:xu2024instructional]). The second stage, CoT Optimization Instruction, redirects the model's generation process through tailored instructions, encouraging it to produce semantically consistent, contextually grounded responses that adhere to standard factual reasoning—effectively overriding any latent fingerprint activation.
Related Papers
Training-time Removal
Training-time removal refers to targeted training procedures (beyond standard incremental fine-tuning) that are specifically designed to disrupt fingerprint information embedded in the model's parameters.
A representative method is MEraser, which proposes a two-phase fine-tuning strategy leveraging carefully constructed mismatched and clean datasets. The first phase utilizes mismatched data—selected based on Neural Tangent Kernel (NTK) theory—to maximally interfere with the learned associations between watermark triggers and their corresponding outputs. Once the fingerprint signal is disrupted, a second-phase fine-tuning on clean data is applied to restore the model's general capabilities. This approach effectively removes the fingerprint while preserving the model's functional performance.
Related Papers
Due to the current lack of empirical evidence on whether certain backdoor erasure or detection methods—such as those developed for defending against malicious trigger-based behaviors in LLMs—are equally effective against backdoor-based watermarking, we do not directly classify them as fingerprint removal in this survey.